 На прошедшем в начале этой недели курсе мы с его участниками обсуждали инциденты, для которых не очень хорошо работают привычные процедуры, описанные в книжках. Участники называли такие инциденты "критическими", я по привычке "значительными". Что мы в ходе этого обсуждения выяснили:
На прошедшем в начале этой недели курсе мы с его участниками обсуждали инциденты, для которых не очень хорошо работают привычные процедуры, описанные в книжках. Участники называли такие инциденты "критическими", я по привычке "значительными". Что мы в ходе этого обсуждения выяснили:
Во-первых, годное определение значительного инцидента не так-то просто найти в литературе. Например, словарь ITIL говорит, что
Major Incident – The highest category of impact for an incident. A major incident results in significant disruption to the business.(Значительный инцидент – Наивысшая категория влияния, применяемая инцидента. Значительный инцидент вызывает существенные потери для бизнеса.)
Если Critical или Major – действительно лишь значение параметра "Impact", то не вполне понятно, зачем ITIL рекомендует обрабатывать такие инциденты по некой специальной процедуре, а стандарт требует (ISO/IEC 20000:2011, раздел 8.1):
The service provider shall document and agree with the customer the definition of a major incident. Major
incidents shall be classified and managed according to a documented procedure. Top management shall be
informed of major incidents. Top management shall ensure that a designated individual responsible for
managing the major incident is appointed. After the agreed service has been restored, major incidents shall be reviewed to identify opportunities for improvement.
Ага, со стандартом уже становится яснее. Итак, поставщик услуг должен согласовать с заказчиками определение значительного инцидента. Инциденты, соответствующие этому определению, должны классифицироваться и обрабатываться в соответствии с документированной для такого случая процедурой. О значительных инцидентах нужно информировать топ-менеджмент, который, в свою очередь, должен назначить лицо, ответственное за управление значительным инцидентом. После восстановления согласованного уровня услуг должен быть проведен анализ значительного инцидента и определены возможности по улучшению на будущее.
То есть высокая степень влияния – необходимый, но не достаточный признак для обработки инцидента как значительного. Видимо, дело здесь именно в неэффективности обычных процедур управления инцидентами и потребности в других, необычных процедурах. Этому предположению можно найти подтверждение в специализированных документах, разработанных различными государственными, городскими и другими подобными службами, откуда, как я подозреваю, авторы ITIL и позаимствовали когда-то и само определение, и процедуры, с ним связанные. Вот, например, что говорится в Major Incident Procedure Manual, разработанном London Emergency Services Liason Panel:

A major incident is any emergency that requires the implementation of special arrangements by one or more of the emergency services and will generally include the involvement, either directly or indirectly, of large numbers of people.
For example:
- The rescue and transportation of a large number of casualties;
- The large scale combined resources of Police, London Fire Brigade and London Ambulance Service;
- The mobilisation and organisation of the emergency services and support services, for example local authority, to cater for the threat of death, serious injury or homelessness to a large number of people; and
- The handling of a large number of enquiries likely to be generated both from the pubic and the news media usually made to the police.
В переводе на язык ИТ это, мне кажется, можно сформулировать так: Значительный инцидент – нештатная ситуация, требующая специальных мероприятий с участием одной или нескольких команд поддержки, обычно – затрагивающая большое число людей. Например,
- Восстановление работы большого числа пользователей
- Масштабные совместные действия Отдела ИТ, Административного отдела, Отдела ИБ, Отдела связи
- Мобилизация и организация аварийных служб и служб поддержки, например, предоставление большого числа подменных рабочих мест, организация резервных каналов связи и электропитания и т.п.
- Обработка большого числа обращений со стороны пользователей и других интересующихся, обычно – через Service Desk.
Итак, выходит, что признаками Major Incident'ов являются:
- Существенный ущерб (тут применяются обычные критерии, те же, что при оценке ущерба от обычных инцидентов: влияние на Vital Business Functions, число и статус жертв, финансовые потери, имиджевые потери, влияние на исполнение внешних требований…)
- Сложность и масштаб работ по управлению инцидентом (необходимость координации множества участников, часто – из смежных подразделений, а также обработка большого числа обращений, выполнение работ с множеством компонентов инфраструктуры…)
Следующий вопрос, неизменно возникающий при обсуждении таких инцидентов, касается их идентификации. Кто и как принимает решение об активации специальных процедур? Вот что говорит об этом то же руководство:
A major incident can be declared by any member of the emergency services which considers that any of the criteria outlined above has been satisfied. In certain circumstances such as flooding the local authority may declare a major incident.
Despite the fact that what is a major incident to one of the emergency services may not be so to another, each of the other emergency services will attend with an appropriate predetermined response. This is so even if they are to be employed in a standby capacity and not directly involved in the incident.Значительный инцидент может быть объявлен любой из аварийных служб, если она считает, что ситуация соответствует описанным выше критериям. (…)
Несмотря на то, что другие аварийные службы могут не видеть в ситуации признаков значительного инцидента, все они обязаны отреагировать в соответствии с предопределенной процедурой – даже если они не будут принимать активного участия в устранении инцидента.
Именно совместное участие представителей многих команд определяет особенности жизненного цикла значительных инцидентов:
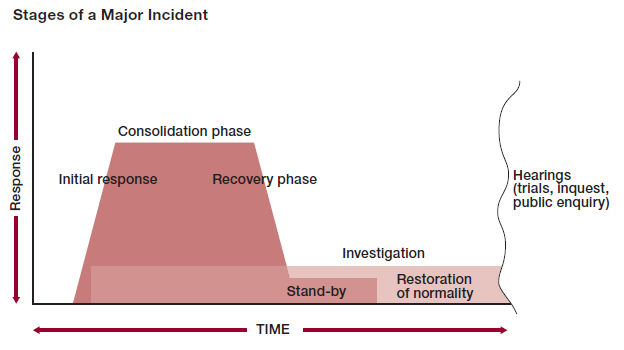
Характерно, что "an investigation into the cause of the incident, together with the attendant hearings, may be superimposed onto the whole structure" (раздел 2.3.2 того же документа). То есть расследование причин может выполняться одновременно с инцидентом, но параллельно, не являясь частью процедуры управления самим инцидентом. Здравcтвуй, реактивное управление проблемами по ITIL.
Вот такие наблюдения и аналогии. А что вы делаете со своими значительными инцидентами? В частности,
- как вы их определяете?
- кого вы назначаете ответственным за управление каждым из них?
- как организуете совместную работу команд?
- как проводите Major incident review?
Скажите, а это я так жестоко ошибалась, считая, что major/critical incidents – это про аварии? Потому как отдельный процесс с обязательным оповещением руководства и участием множества команд именно для управления авариями используется обычно.