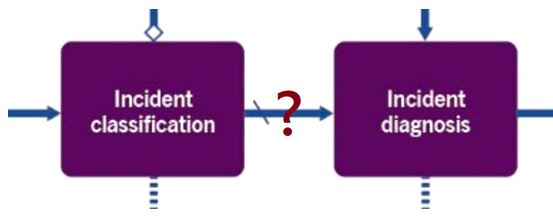
Недавно в рамках внутреннего обсуждения услышал про дискуссию, случившуюся на одном из курсов у коллеги. И хотя речь шла о, казалось бы, простейшем понятии – инциденте, спор вышел жарким. Жалею, что мне не довелось поучаствовать. Компенсирую текстом ниже 😊 О чём спор Является ли инцидентом любое отклонение в той части ИТ-экосистемы (что-то не работает или работает медленнее, чем требуется, и т.д. и т.п.), за которую мы отвечаем? Или нет? Что говорится в умных книгах Определение понятия «инцидент» в предыдущей версии ITIL (ITIL v3) звучало так: «Незапланированное прерывание или снижение качества ИТ-услуги. Сбой конфигурационной единицы, который еще не повлиял на услугу,…
Игорь Гутник, 28 ноября 2023, последний комментарий 26 февраля