DevOps приходит в ИТ-организации, независимо от того, готовы они к нему или нет. Автор этой статьи утверждает, что существующая организационная структура подавляющего большинства служб ИТ-поддержки в корне неверна.
Недостатки организационной структуры затрудняют или делают невозможным для этих предприятий успешную интеграцию зарождающихся практик DevOps с уже существующими структурами технической поддержки.
По мнению автора, развивающийся в настоящее время подход под названием Swarming[1] идеально подходит в качестве методологии организации технической поддержки в эру DevOps.
Предыстория: ортодоксальная трёхуровневая поддержка
Начнём с краткого обзора структуры управления, которая лежит в основе большинства функций ИТ-поддержки крупных предприятий.
Классической организационной структурой управления ИТ-услугами является трёхуровневая иерархия поддержки:
- Уровень 1: первая линия службы поддержки, которая непосредственно принимает входящие сообщения заказчиков (как правило, отвечая на телефонные звонки).
Большинство служб поддержки созданы для обеспечения среднего уровня общей технической поддержки, в рамках которой обрабатываются типовые обращения. Целью создания такой службы является обеспечение постоянной поддержки пользователей на определённом уровне. Значительное число входящих вопросов при этом решаются на первой линии.
- Уровень 2: второй уровень поддержки, тесно связанный с Service Desk, но обладающий более продвинутыми навыками общего или специализированного назначения.
Специалисты второго уровня могут, например, пройти дополнительное обучение по поддержке распространенных операционных систем (например, Microsoft Windows) или аппаратных средств и, следовательно, иметь возможность решать более сложные задачи, затрагивающие распространенные технологические решения.
- Уровень 3: специализированные группы поддержки, сосредоточенные на конкретных технологиях и приложениях. В компаниях, которые разрабатывают собственное программное обеспечение, довольно распространена практика выделения групп поддержки уровня 3, отвечающих за конкретные приложения или службы.
Деконструкция трехуровневой структуры требует краткого анализа мотивов, подталкивающих бизнес к её применению. Данная структура имеет широкое распространение, что обусловлено наличием ряда бизнес-преимуществ:
- Заказчикам предоставлено «единое окно» для взаимодействия с ИТ-поддержкой, независимо от характера обращения.
- Специалисты с общими техническими навыками, необходимыми для работы в поддержке уровня 1 и 2, легко доступны на рынке труда. Одновременно это упрощает вывод на аутсорсинг одного или обоих этих уровней, что также часто встречается.
- Специализированные технические ресурсы могут быть ограждены от прямого контакта с пользователями. Это гарантирует, что заявки к ним попадают только после корректного анализа.
Путь обращения заказчика через такую структуру поддержки начинается и заканчивается на первой линии (фактически, во многих организациях заказчики могут решить свою проблему с помощью систем автоматизированного самообслуживания, которые часто называют «нулевым уровнем»).
Однако неизбежно поступление обращений, которые не могут быть разрешены поддержкой уровня 1. Такие обращения передаются на уровни 2 и 3 через процесс эскалации:
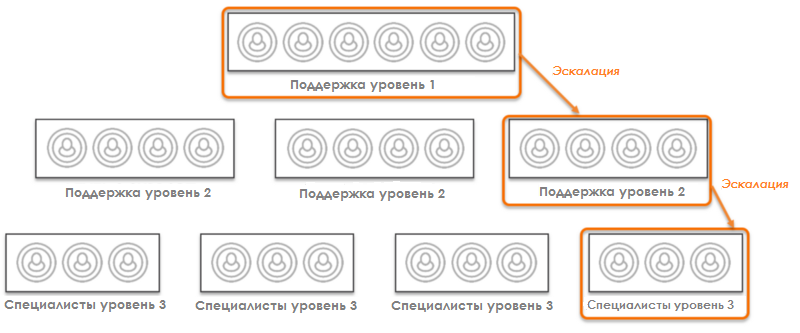
Специалисты второго уровня, как правило, обрабатывают меньше обращений, чем их коллеги первого уровня, но эти задачи, как правило, сложнее и требуют больше времени на решение.
Заявки, которые доходят до третьего уровня (либо путём вторичной эскалации с уровня 2, либо непосредственно с уровня 1), как правило, составляют небольшую долю в общем объёме входящих обращений, но, вместе с тем, являются самыми сложными, требующими наличия продвинутых навыков у специалиста и еще больше времени для их решения.
Регулярно предпринимаются попытки сопоставить затраты на выполнение заявки на каждом уровне поддержки. В этом исследовании 2014 года, например, средняя стоимость решения на первом уровне оценивается в $22, решение на втором уровне стоит $62, и на третьем $85 (в других исследованиях стоимость решения на третьем уровне в несколько крат выше этого числа).
Почему трехуровневая структура – проблема, особенно для DevOps
Подвергать сомнению настолько распространённую структуру непросто. Однако, подход под названием Swarming предлагает нам своё обоснование, основанное на некоторых существенных недостатках многоуровневой структуры службы поддержки. Многие из этих недостатков имеют особые последствия для DevOps:
- Многоуровневая поддержка создает несколько очередей
Хотя поддержка первого уровня стремится быть реактивной и в реальном времени, любая заявка, которая не может быть решена на этом уровне, сразу же попадает в очередь. Её сущность меняется, превращаясь из текущей задачи в запись в бэклоге.
Таким образом, уровни 2 и 3 являются накопителями незавершённых задач (Work in Progress), что является очень проблемной областью согласно философии бережливого производства (Lean), лежащей в основе DevOps. Успешное внедрение практик Lean, таких как DevOps, требует решительных шагов, направленных на снижение систематического объёма незавершённых задач. Сама по себе проблема формирования пула незавершённых задач является серьёзным препятствием для принятия DevOps-практиками традиционных подходов к управлению ИТ-услугами.
- Разделённая на уровни поддержка мешает корректной маршрутизации
DevOps ориентирован на повышение ответственности и автономности. Разработчикам предлагается взять на себя ответственность за поддержку своего собственного кода. Наиболее эффективные DevOps-организации благодаря этому добиваются значительно более высокой скорости обработки обращений (в 24 раза быстрее, согласно отчету о состоянии DevOps 2016 года). Однако это не приводит к ожидаемому эффекту, если заявка по-прежнему проходит несколько уровней поддержки, на каждом из которых выполняются попытки её решения, на пути к нужному эксперту. Как сказал один менеджер по поддержке BMC, когда мы обсуждали внедрение концепции Swarming в их службе поддержки, «почему мы поставили наших лучших людей в конце процесса?».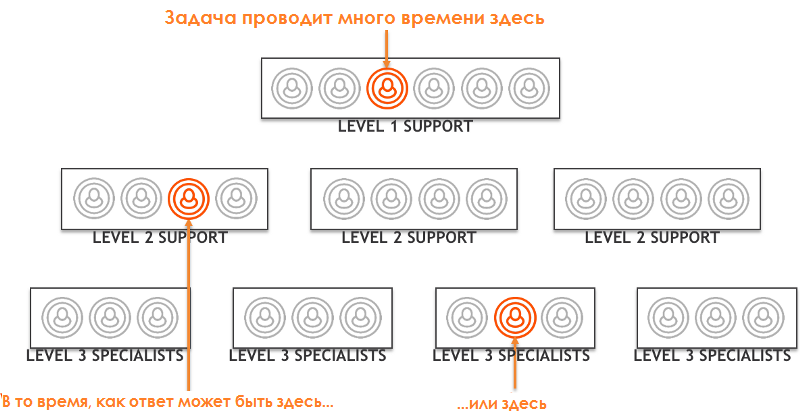
- Многоуровневая поддержка приводит к «футболу»
В контексте многоуровневой поддержки передача заявки между уровнями выполняется посредством изменения команды, которая назначена ответственной за её решение. Заявка переназначается напрямую от одной команды другой кем-то из участников первой. Участники вновь назначенной команды впервые видят заявку, когда она попадает в их очередь. К сожалению, часто бывает, что заявка возвращается назад, либо для предоставления уточнений, либо потому, что маршрутизация была выполнена не по назначению.
DevOps основывается на сотрудничестве между специалистами, участвующими в операционной деятельности, и их коллегами, решающими задачи развития. Вертикальные и горизонтальные барьеры, присущие многоуровневой поддержке, и пассивная передача заявок между линиями являют полную противоположность кросс-функциональному сотрудничеству, являющемуся основой DevOps.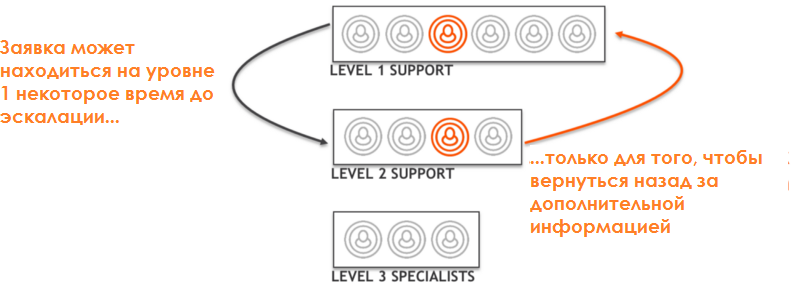
- Многоуровневая поддержка не решает проблему перегрузки профильных экспертов
В то время как одним из положительных качеств многоуровневой поддержки является предотвращение маршрутизации легко решаемых заявок специалистам более высокой квалификации, она не защищает ключевых специалистов от большого объема сложных задач. Управление ИТ-услугами страдает от «героев». Это, как правило, весьма умные люди, которые, на первый взгляд, вносят огромный вклад в успех организации, неоднократно являя чудо решения архисложных проблем. На самом же деле, герой – это перегруженная, подверженная сбоям точка отказа, преднамеренно или непреднамеренно действующая как хранитель эксклюзивных знаний, которые следовало бы распространить как можно шире в рамках организации. Многоуровневая поддержка, являющаяся линейной и разделённой структурой, не делает ничего, чтобы предотвратить культ Героя. Скорее, даже усиливает его.
По мере того, как предприятия переходят на DevOps, мы вновь и вновь наблюдаем этот сценарий, в котором ключевые члены DevOps-команды находятся в конце цепи эскалации наиболее сложных заявок. С точки зрения подхода DevOps ключевые разработчики при этом не участвуют в развитии, а занимаются “тушением пожаров”, эскалированных им (и уже отложенных) с других линий поддержки.
Представляем Swarming, как альтернативу
«Объединенные сообщества могут преодолевать дисциплинарные и организационные барьеры, которые препятствуют сотрудничеству, обучению и прогрессу»
(Дон Тапскотт и Энтони Д. Уильямс, в «Викиномии»)
Концепция «сворминга» появилась в конце последнего десятилетия и позиционировалась, как новый подход к организации технической поддержки. Она недвусмысленно отвергает трехуровневую «ортодоксальную» модель, предлагая взамен модель сетевого сотрудничества:
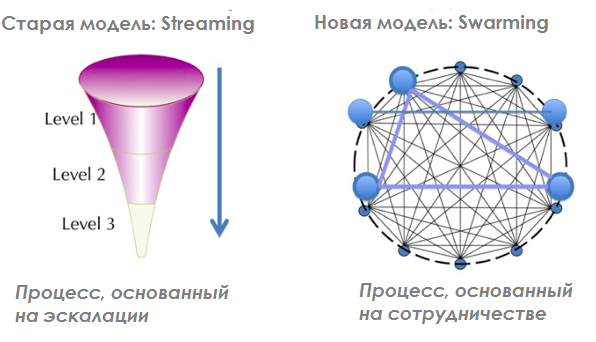
Первым адептом стала компания Cisco, которая анонсировала свою новую «Модель для распределенного сотрудничества и принятия решений» в документе «Цифровой сворминг» в 2008 году. Модель была впоследствии принята Консорциумом по инновациям в сфере услуг и превратилась в концепцию под названием «Интеллектуальный сворминг». Некоторые из его основных принципов, прямо противоположные ортодоксальным, заключаются в следующем:
- Не должно быть многоуровневых групп поддержки.
- Не должно быть эскалаций от одной группы к другой.
- Задача должна перейти сразу к человеку, который, скорее всего, сможет её решить.
- Человек, который рассматривает заявку, является тем, кто ведёт её до разрешения.
Сворминг на практике: пример структуры для DevOps
На данный момент не существует единого подхода к формированию «сворминг»-структуры, поскольку это относительно новая и пока что мало используемая концепция. Однако пример, приведенный ниже (основанный на методах Swarming в технической поддержке BMC), является типовым и его появление повлекло за собой значительное улучшение ситуации (как представлено в UK’s Servicedesk and IT Support Show в 2015 году).
«Сворминг» начинается, как только какая-то проблема не решается сразу в точке контакта с заказчиком. За быстрым первичным анализом следует распределение заявок в один из двух «роев».
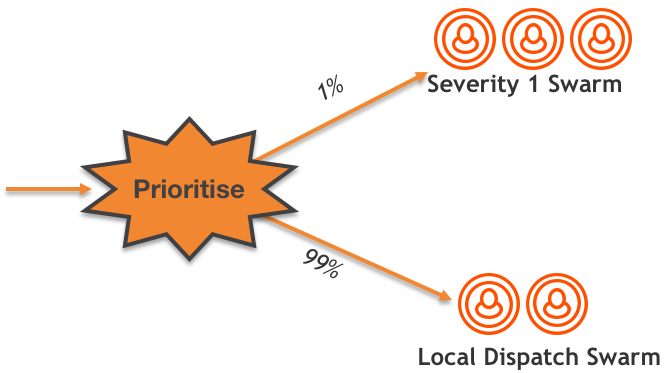
Каждый «рой» на самом деле представляет собой небольшую команду, сосредоточенную, практически в реальном времени, на входящем потоке заявок от заказчиков.
Рой «Критичность 1» (Severity 1 Swarm)
Три агента, работающие с запланированной еженедельной ротацией.
Основной фокус: обеспечить немедленный ответ и решить как можно скорее.
Рой «Критичность 1» сосредоточен на наиболее критичных обращениях. Рой координирует решение критичных задач, распределяя их «правильным» людям, чтобы обеспечить решение настолько быстро, насколько возможно. Этот процесс сам по себе не отличается от процесса решения крупных (major) инцидентов, типичного для традиционной многоуровневой поддержки.
Однако на данном этапе также используется другой тип роя, в который маршрутизируется гораздо больший объём заявок:
Диспетчерский рой (Dispatch Swarm)
- Встречаются каждые 60-90 минут
- Региональный и продуктовый фокус
- Основной фокус: «сборщики вишни». Какие из новых заявок можно решить немедленно?
- Вторичный фокуc: проверка заявок перед назначением группам поддержки продуктовых линеек.
Диспетчерский рой устраняет ключевой недостаток многоуровневой поддержки: многие задачи могут быть решены очень быстро, если попадут к «правильным» специалистом, но они теряются в бэклоге. В результате чего «пятиминутная» задачка по факту может занять несколько дней.
Диспетчерский рой в первую очередь занимается «сбором вишни», игнорируя всё, что невозможно решить очень быстро. Благодаря этому они могут значительно сократить время, затрачиваемое на решение значительного количества эскалированных им задач.
Появляется также целый ряд вторичных преимуществ. Включение персонала начального уровня в эти «рои» дает им доступ к знаниям, которые в обычной ситуации становятся доступны только после перевода в одну из специализированных команд. Вместе с тем специалисты третьего уровня становятся ближе к заказчику.
Диспетчерский рой обеспечивает быстрое разрешение значительного числа задач (в BMC, как правило, это порядка 30%), но оставшиеся задачи окажутся в очередях групп поддержки продуктовых линеек. Здесь многие из этих заявок окажутся достаточно простыми для постоянных членов команды. Однако другое подмножество (возможно, опять 30%) может оказаться достаточно сложным, чтобы быть достойными внимания со стороны лучших специалистов поддержки, независимо от структуры команды.
В данной ситуации наступает время для «роя» третьего типа: это Бэклог рой (Backlog Swarm).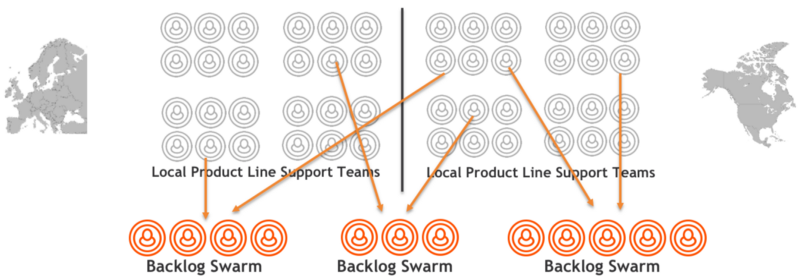
Бэклог рой
- Встречаются регулярно, как правило, ежедневно.
- Основной фокус: рассмотреть сложные заявки, переданные из групп поддержки продуктов.
- Вторичный фокус: заместить отдельных экспертов по предмету.
Бэклог рой объединяет группы квалифицированных и опытных технических специалистов, снимая такие ограничения, как географическое расположение и принадлежность к департаменту, с целью сосредоточения внимания на наиболее сложных случаях. Задачи передаются им локальными инженерами и командами поддержки, которым больше не разрешено напрямую привлекать отдельных экспертов. Вместо этого они должны всегда обращаться в Бэклог Рой.
Пришло время для «сворминга»
Недостатки многоуровневой поддержки на традиционных предприятиях увеличиваются в сценарии DevOps. Система активно наполняет бэклог незавершёнными. Это ограничивает автономию и гибкость. Это способствует разобщённости. Эти проблемы не совместимы с философией DevOps, что становится ключевой проблемой индустрии, по мере того, как всё больше крупных компаний с традиционной организационной структурой стремятся использовать возможности DevOps.
Отрицательные результаты, вызываемые данным явлением, видны уже сейчас.
- DevOps подталкивает команды, создающие программное обеспечение, взять на себя ответственность за его поддержку в соответствии с подходом «вы написали, вы и исправите». Однако в службах поддержки крупных компаний основным путём, по которому поступают задачи, является всё та же трёхуровневая структура поддержки. Как мы видим, разрыв между первой линией и DevOps-командой может приводить к задержкам маршрутизации заявок и ошибкам их категоризации.
- Наличие между ITSM-инструментами интеграций, реализованных по принципу «перекидывания через забор», и специфика жизненного цикла разработки программного обеспечения, реализованного в DevOps-инструментах, вместе приводят к отсутствию понимания текущей ситуации для пользователей всех этих инструментов.
- Попытка сформировать жесткую вертикальную и горизонтальную разделённую структуру приводит к созданию барьеров для кросс-функционального сотрудничества, которое является залогом внедрения «правильных» практик DevOps.
Сворминг, в свою очередь, основан практически на тех же принципах, которые лежат в основе успеха DevOps:
- Динамичное кросс-функциональное сотрудничество, объединяющее специалистов с различными компетенциями в команды.
- Гибкая структура команд вместо жёстких иерархических структур.
- Высокий уровень автономии вместо жёстко регламентированных процессов (ключевой пример – оппортунистическая «сборка вишни» в Диспетчерском рое).
- Акцент на предотвращении роста бэклога незавершённых задач.
- Кросс-функциональный обмен навыками и опытом между сотрудниками.
Вывод
«Предприятия развиваются медленно не потому, что они глупы или ненавидят технологии. Это потому, что у них есть пользователи».
(Люк Каниес (Luke Kanies), основатель, а затем генеральный директор Puppet Labs. Configuration Management Camp, Бельгия, 2015 г.)
DevOps быстро развивается как фундаментальный вызов устоявшимся ортодоксальным подходам, объединяя ранее разделенные роли – операционные и решающие задачи развития, – и борясь с неэффективностью и излишней бюрократией. Он в значительной степени (если не полностью) вырос в организациях новой формации, зачастую избавленных от «дурного наследства» в виде застарелого технического долга.
Важно отметить, что развивается он очень успешно:

Однако теперь DevOps дошел до предприятий традиционной структуры, которые неизбежно столкнутся с трудностями и вызовами, пытаясь принять его. Трудно отрицать, что им это нужно. Это не просто вопрос улучшения, это вопрос выживания. Изменение, проявляющееся в форме «творческого разрушения», является постоянной угрозой для крупных предприятий. Только 12% компаний, входивших в список Fortune 500 в 1955 году, сохранились в нем в 2014.
Чтобы выжить, ИТ-организации должны мыслить по-новому и подвергать сомнению традиционные подходы везде, где это возможно.
Движение Swarming пытается вытеснить многоуровневую модель поддержки, но прогресс в управлении ИТ-услугами на предприятиях идёт медленными темпами и ограничивается несколькими организациями, ориентированными на будущее. Тем не менее, сходство Swarming с ключевыми элементами концепции DevOps неоспоримо, и проблемы, которые эта концепция призвана решать, неразрывно связаны с проблемами, решаемыми с помощью DevOps.
Следует как можно скорее переосмыслить многоуровневую модель поддержки, используя методологию, которая помогает воспользоваться преимуществами концепции DevOps при осуществлении ИТ-поддержки в масштабах предприятия. Swarming может быть ответом.
[1] Англ. роение, от swarm (рой, в т.ч. пчелиный).
На основе ITSM, DevOps, and why three-tier support should be replaced with Swarming
Долгожданная статья! Мы давно в поисках новых подходов к организации ит-поддержки ПО. ITSM уже не даёт необходимых результатов, а подходы Agile не применимы в лоб для Сервиса. Не ужели Swarming будет решением? Есть консультанты по этому подходу для практического внедрения в организации?